原文:https://dougshapiro.substack.com/p/with-sora-ai-video-gets-ready-for-closeup
时间:2024 年 2 月 26 日
作者:道格·夏皮罗(Doug Shapiro),独立顾问/咨询专家,BCG 高级顾问,前 Turner/WarnerMedia 分析师
翻译:Horace Lu
(注:键盘快捷键“w”或左侧菜单右上角按钮,可切换文章列表视图与大纲视图)

在 2022 年 12 月,我撰写了 《电视启示录的四骑士》 一文,其中提到包括生成式 AI(GenAI)在内的技术可能会在未来 5 至 10 年内模糊独立创作内容与专业制作内容的质量界限,从而导致“无限”质量视频内容的涌现。关于此话题的更多专栏文章,请参阅:《好莱坞的颠覆进程将如何展开?》 及 《生成式 AI 对好莱坞而言是持续性还是颠覆性创新?》
一年前这还只是一个抽象理论,但随着上周 OpenAI 发布 Sora,这一理论变得越来越接近现实,而且原先预估的 5-10 年时间似乎过于保守,科技进步的速度远超预期。
在这篇文章中,我将探讨为什么 Sora 如此重要,以及它所涉及的关键问题。
摘要
讨论 AI 颠覆好莱坞的可能性时,重要的是明确“颠覆”与“AI”的具体含义是什么。
这里的“颠覆”指的是克莱·克里斯腾森(Clay Christensen)提出的低端颠覆(low-end disruption)理论,该理论提供了一个精确框架,来研究颠覆如何发生及其带来的影响。
并非所有的“AI”都一样。一些 AI 工具被用作持续创新,以提高现有工作流程的效率。而像 Runway Gen-2、Pika 1.0 和 Sora 这样的 AI 视频生成器(或称为“X2V”模型)则具有更深远的颠覆潜力,因为它们代表了一种全新的视频制作方式。
当前行业正处于风口浪尖。虽然克里斯腾森并未详细说明决定颠覆速度和程度的具体因素,但对于好莱坞来说,这种颠覆可能既快速又深远。
这是因为创作者内容已经在从低端市场开始挑战好莱坞的地位(在美国,YouTube 是最受欢迎的电视流媒体服务,CoComelon 和 Mr. Beast 在各自类型中是全球最受欢迎的节目)。因此,X2V 模型可能会加速这一进程;创作者内容的总量已经十分庞大,即便只有极小比例的内容能够达到与好莱坞匹敌的质量水平,也足以改变供需动态;同时,消费者接纳这类技术的技术门槛几乎不存在。
尽管在过去的一年中,X2V 模型取得了显著的进步,并具有潜在的颠覆能力,但目前它们尚未达到这一目标。它们存在的问题包括:缺乏时间一致性、动作卡顿、输出视频长度受限、无法捕捉人类情感、不能为创作者提供精细控制、无法实现口型与对话同步等。
Sora 之所以给整个行业带来震撼,是因为它一举解决了上述许多问题。根据我对 Sora 技术论文的外行解读,其关键创新在于,结合了 Transformer 模型和 Diffusion 模型(使用视频“补丁”),同时结合了压缩技术,以及 ChatGPT 对于语言的微妙理解。
虽然 Sora 并不完美(且当前还未商业化),但它传递的主要信息是,视频生成是一个可解决的问题。鉴于开源研究的广泛性,模型组件的复用性,以及额外数据集规模和算力带来的显然是无尽的好处,这些模型只会越来越好。
对于好莱坞而言,Sora 无疑敲响了警钟。对于价值链中的每个人来说,理解这些工具、接纳它们,并弄清楚在高质量资源日益丰富的情况下什么将会变得稀缺,是至关重要的。
精准定义“颠覆”
在过去的一周里,许多人声称好莱坞即将“被颠覆”,但明确这个术语的确切含义十分重要。
颠覆一词在日常用语中有广泛的含义,即:根本性的变革。而在克莱·克里斯腾森(Clay Christensen)关于颠覆性创新的理论中,颠覆有着更为具体的定义:颠覆是指新进者通过一款“起初较为劣质,但会逐步改进,并最终挑战现有市场主导者的创新产品”进入市场的过程。
若将“好莱坞会被颠覆”理解为广义上的彻底改变,那么这种表述过于模糊且缺乏实质意义,就如同气象预报员说“一场大风暴即将到来”。这场风暴有多猛烈?是带伞防小雨的程度,还是必须避免出行、封闭门窗、囤积沙袋、疏散人群,甚至可能导致再也无法获得房屋保险的重大灾害程度?是在明天、下周二、一个月后,还是一年后发生?
像往常一样,在我使用这个词时,指的正是克里斯腾森更为精确的定义。这一定义为我们提供了一个框架,以评估这一过程是否可能发生,以及可能产生的影响。
“X-to-Video”模型具有最大的颠覆潜力
在讨论 AI 对好莱坞的潜在影响时,明确我们正在谈论的是哪种类型的 AI 也至关重要。最具颠覆潜力的是 AI 视频生成器,也被称为文本转视频(T2V)、图像转视频(I2V)和视频转视频(V2V)模型。为了方便,我将它们统称为 X-to-video(X2V)模型。
克里斯腾森区分了持续性创新和颠覆性创新。前者使现有企业能够更好或更低成本地完成工作(比如剃须刀上的第五片刀片),后者则降低了准入门槛并催化了颠覆过程(比如邮购剃须刀刀片的订阅业务模式)。技术本身并不固有地属于其中任何一种类型,而是取决于其如何被应用,但有些技术比其他技术拥有更大的颠覆潜力。
用于改进现有制作流程效率的 AI 工具
正如我在 生成式 AI 对好莱坞而言是持续性还是颠覆性创新? 中描述的那样,许多 GenAI 工具正被用于改进现有制作流程的效率,这符合持续性创新的定义。例如:
Flawless 利用 GenAI 技术实现电影级别的高质量“配音”,使得任何演员的声音听起来就像母语一样自然。
VFX 工作室 MARZ 引入了 Vanity AI 以及其他工具,大大减少了“数字化妆”(去除演员面部瑕疵和衰老迹象)所需的时间和成本。
Cuebric 使用 GenAI 快速生成虚拟拍摄时 LED 面板上显示的背景环境。
Adobe 正在将其 GenAI 工具(如 Firefly)嵌入现有的编辑套件如 Photoshop、Premiere Pro 和 After Effects 中,以自动化并加速现有工作流程。
此外,可以利用文本转图像(T2I)生成器,如 Midjourney 或 DALL-E,以更快捷且经济的方式创建故事板或其他概念艺术作品。
当前,制作优质内容的成本高昂且劳动密集度极高,一部电视剧或电影往往需要数百甚至上千名工作人员的合作。根据这些趋势粗略估计,这类工具结合使用后,最终可能将制作一部电影级别的影视作品所需时间压缩 30%至 50%,并且有可能同样程度地减少人力需求。随着时间推移和技术进步,这一改善幅度可能会更大。
X2V 模型
X2V 模型,如 Runway、Pika、Genmo(Replay)、Kaiber、尚未发布的谷歌模型(Lumiere)以及开源模型如 Stable Video Diffusion 等,代表了一种更具颠覆性的趋势。与持续性创新不同,X2V 模型提供了一种全新的视频制作方式,其成本仅是传统方式的九牛一毛。
这些模型采用了完全不同的工作流程,不再需要演员、导演、制片人、布景设计师、创意总监、制片助理、灯光师、机械组长等传统角色;只需要一位勤奋、有动力和创造力的个人,配备一台笔记本电脑、少量预算,也许还需要一些剪辑技能。正如 Runway 自豪地宣称:

因此,与其他 GenAI 视频应用相比,X2V 模型更有潜力大幅降低创作高质量内容的门槛,从而模糊创作者或独立内容与好莱坞制作之间长期以来的质量界限。
理论上,这种颠覆如图 1 所示。以红色 YouTube 线为代表的独立内容,首先会吸引需求最低端的消费者群体(如儿童),然后随着性能曲线的提升,逐渐吸引次低需求层级的消费者(如真人秀观众)。X2V 模型有望助力创作者内容继续沿着性能曲线向上攀升,挑战好莱坞更高品质的内容制作,并争夺更挑剔的用户群体。
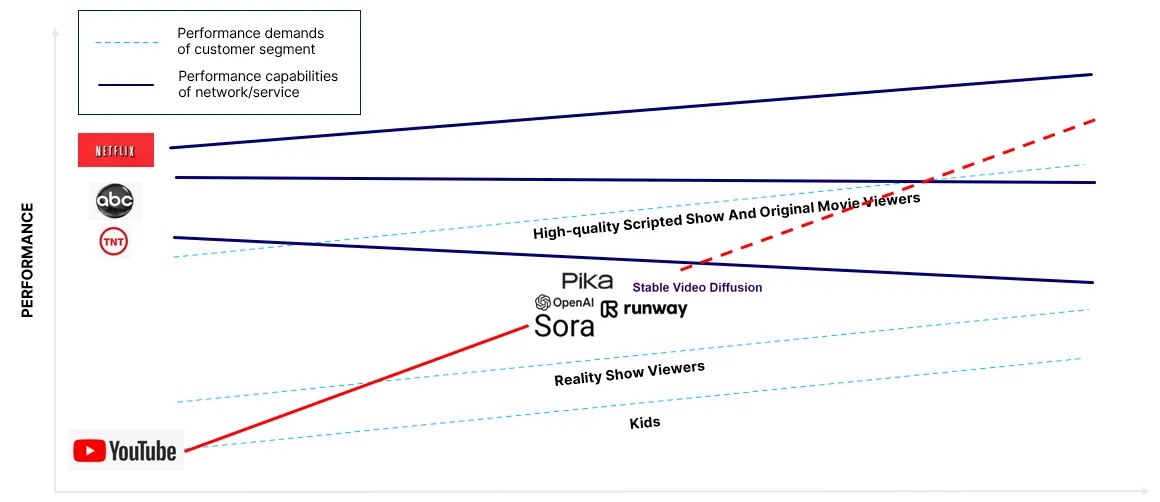
因此,虽然理论上 X2V 模型能让创作者制作出更高品质的内容,但迄今为止它们尚未达到这一水平。生成的视频效果虽有趣,但在字面意义和比喻意义上都还没有准备好在黄金时段播出。你我都不会选择在晚上 8 点坐在沙发上观看 AI 生成的视频。按照定义来说,所有颠覆性创新在起步阶段都是“不够好的”,或者说质量较差的。但反过来并不一定成立,仅仅因为某样东西质量差,并不意味着它注定会成为颠覆性创新。
关键问题在于:这些模型能否生成人们愿意观看的内容?如同 Diffusion 模型能够对图像进行去噪处理一样,Sora 以及最近其他几项创新成果的发布,使得这个问题的答案更加清晰。
消费者对 AI 视频的接受速度可能非常快
在深入探讨 Sora 的影响之前,让我们先回顾一下好莱坞所面临的风险。
正如我在之前的文章 《好莱坞的颠覆进程将如何展开?》 所述,颠覆的速度和程度可以各有不同,有时快速且彻底(老牌企业被完全或几乎完全挤出市场),有时缓慢而部分发生(老牌企业失去了低端市场,但仍保留有利润丰厚的高端市场)。在那篇文章中,我指出了 几个决定颠覆程度和速度的因素:
- 新进入者向高端市场发展的难易度。
- 消费者接纳竞品的难易度。
- 竞品引入的新特性改变消费者对质量定义的程度。
- 老牌企业的惰性程度。
- 高端市场的规模和持久性。
当前情况下,后三点难以立即得出结论。我们尚不清楚 AI 视频将如何改变消费者行为,以及消费者如何重新定义质量;我们还不知道老牌企业会作何反应(尽管 我曾写过,我认为他们准备不足,这在很大程度上是由于其运作的复杂生态系统,包括人才、经纪公司、工会等);我们也不清楚传统专业视频制作的“高端”市场最终能有多大规模或多持久。
在下文中,我将讨论 Sora 针对第一点,即 AI 生成视频向上游市场发展难易度,所带来的启示。
不过,我们先花一点时间关注第二点:消费者转向观看 AI 创作或增强视频可能会非常迅速,原因如下:
- 创作者内容的对好莱坞的颠覆已经在进行中,GenAI 只是火上浇油;
- 创作者内容的总量庞大到令人震惊;
- 接受 AI 视频的门槛几乎不存在。
低端市场颠覆正在进行中
创作者内容正在从底部颠覆好莱坞行业。以下是尼尔森最新的“Gauge”图表(图 2),我在其他文章中也曾引用过这张图表。图表显示,在美国最大的电视流媒体服务是 YouTube。(值得注意的是,这一数据并未计入移动设备或桌面端的使用量,以及 YouTube TV 的数据)。这意味着美国家庭通过电视观看 YouTube 的时间超过了 Hulu、Disney+、Peacock、Max 和 Paramount+ 的总和。
多年来,许多人认为或希望 YouTube 不会对传统电视构成威胁,因为它满足的是完全不同的使用场景。但这些数据显示,这种观点被直接否定,因为其应用场景与传统电视完全相同:在电视机上观看。
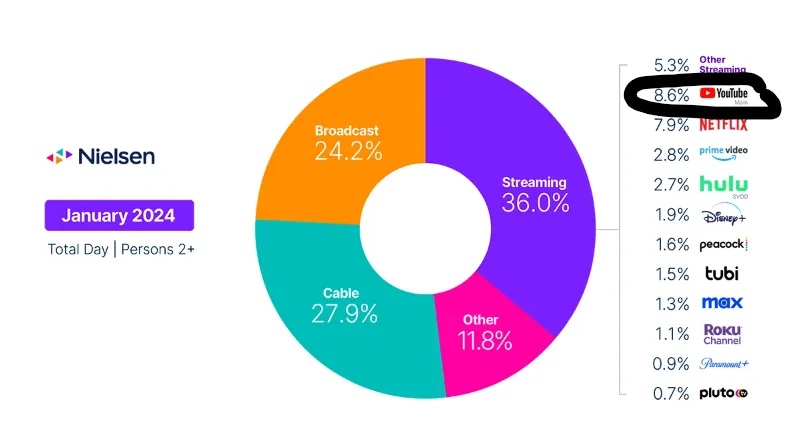
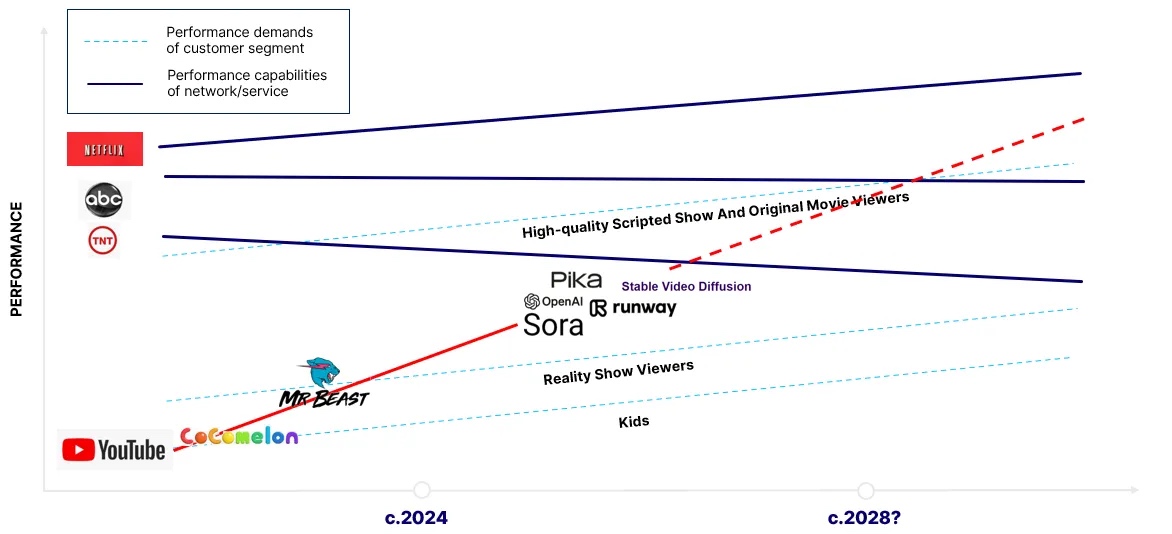
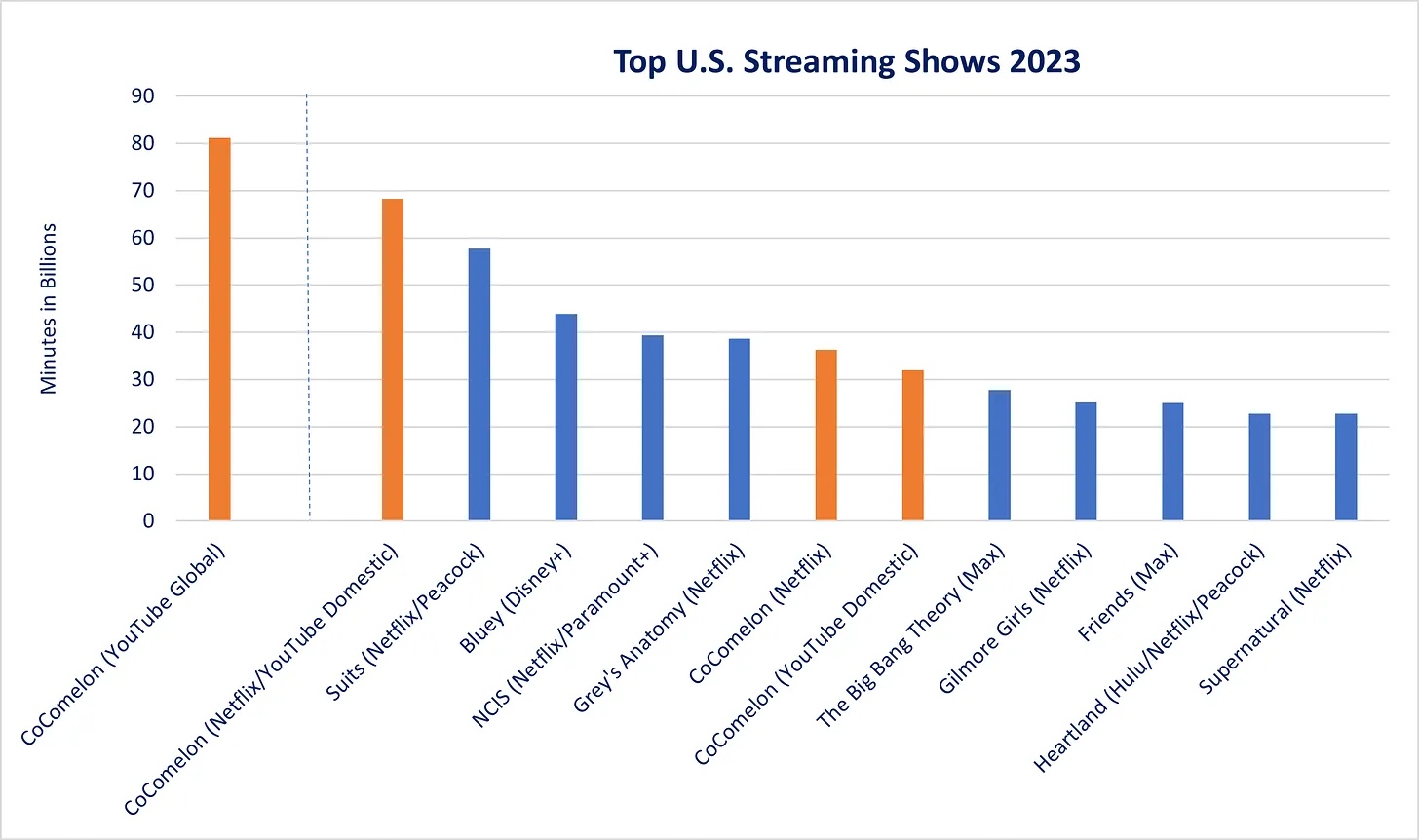
图 3 展示了稍作修改的先前图表,正如底部的 CoComelon 和 Mr. Beast 标志及其日期所示的那样,在 X2V 模型出现之前,独立内容已经在性能曲线上不断攀升,并从底层开始对好莱坞产生颠覆性影响。根据观看时长衡量,同时在 YouTube 和 Netflix 上线的“CoComelon”,可能是全球最受欢迎的儿童节目。图 4 引用了尼尔森的数据,显示了去年美国高端流媒体服务上收视率最高的节目;同时也基于 Social Blade 数据,给出了我对 CoComelon 在 YouTube 上国内外总观看分钟数的大致估算。需要注意的是,仅在美国国内,Disney+上的《Bluey》观看量超过了 Netflix 上的 CoComelon,但如果加上美国地区 YouTube 上 CoComelon 的观看量,它就成为了全美观看次数最多的节目,甚至超过《金装律师》(Suits)。据估计,CoComelon 去年在全球范围内被观看了约 800 亿分钟,因此很可能也是全球最受欢迎的儿童节目。
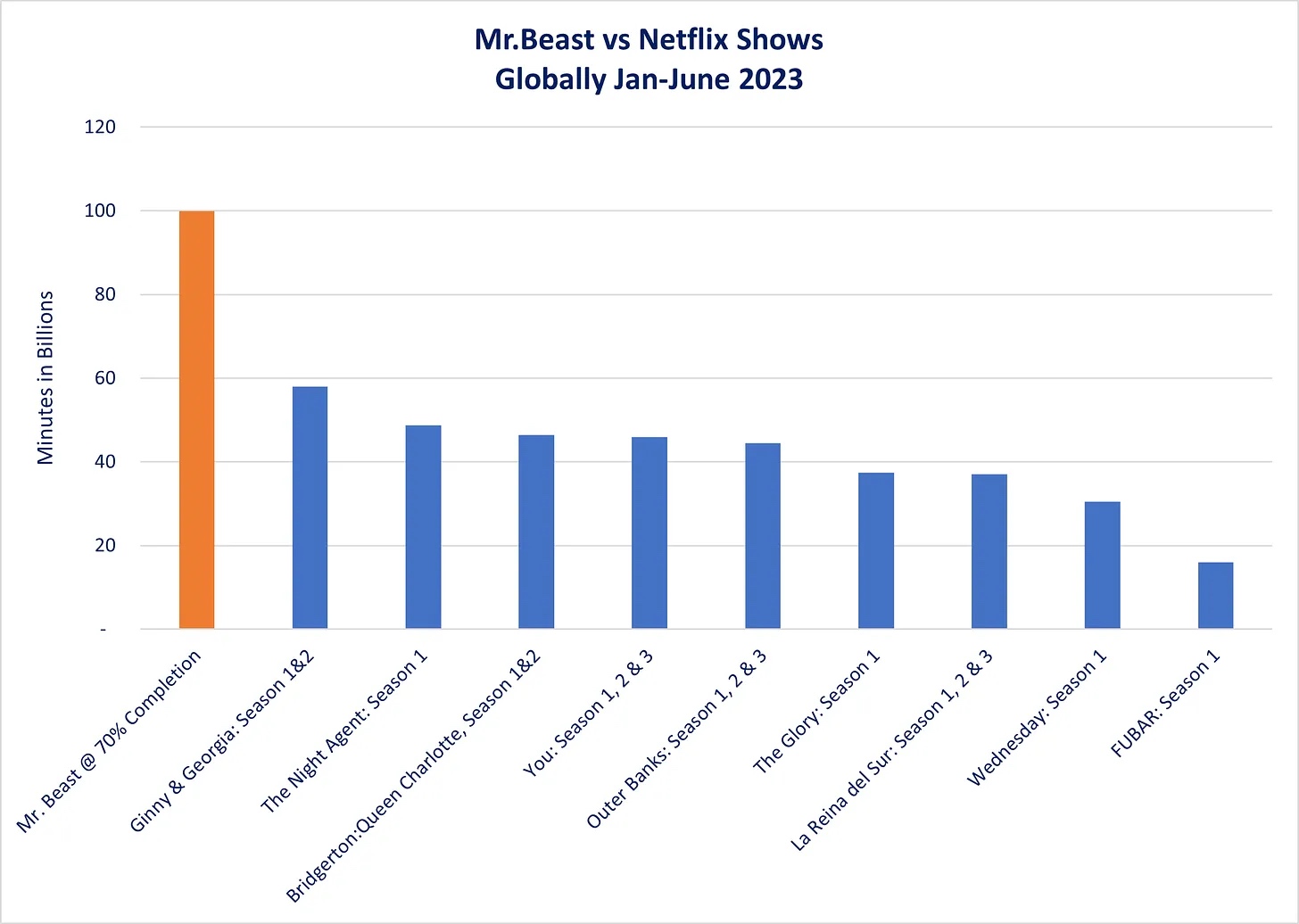
同样地,如果我们把 Mr. Beast 主频道上的视频合集 [1] 视为“一档节目”,那么 Mr. Beast [2] 则可能是全球最热门的节目。图 5 依据 Netflix 最近发布的《What We Watched》报告,展示了去年 1 月至 6 月全球 Netflix 平台上观看次数最多的节目。(请注意,该图表为了便于比较,合并了所有热播剧集的各季数据。)此外,该图还基于 VidIQ 提供的平均视频长度 18.98 分钟以及预估的 70% 完成率,对同一时期内 Mr. Beast 节目的观看情况进行估算。如图所示,在 2023 年上半年,Mr. Beast 节目的观看量可能接近 Netflix 上观看次数最多的剧集《金妮与乔治娅》(Ginny & Georgia)的两倍。
创作者视频的颠覆力量势不可挡
有时,一个行业可能仅被一个成功的颠覆者所改变。例如,我认为付费电视价值链主要由 Netflix 一家公司颠覆。然而,在当前情况下,我们面临的是数以千万计的颠覆者:独立创作者。创作者内容的庞大规模令人震撼。
我在其他文章中引用过这些数据,但它们值得再次强调。我(慷慨地)估计去年好莱坞制作了大约 15000 小时的原创电视剧和电影。相比之下,YouTube 在 2019 年披露,每分钟有创作者上传 500 小时的视频到该平台(这一数字现在肯定更高),即每年超过 2.5 亿小时。即使只有 0.01%的此类内容被认为与好莱坞制作具有竞争力,这也意味着 30000 小时的内容产出,已经是好莱坞年产量的两倍。如果 0.1%的内容被证明具有竞争力,则是其 20 倍之多。
消费者接纳 AI 视频的门槛几乎不存在
没有什么能阻止 AI 视频迅速变得流行。为了比较,我们可以考虑 Netflix 颠覆付费电视所需经历的过程:
- 几乎普遍存在的宽带网络。
- 消费者对宽带的广泛接入(即接受度)。
- Netflix 需要买入或制作足够吸引消费者订阅的优质内容。
- 联网电视(connected TVs)几乎无处不在的普及率。
- 消费者行为的转变,即逐渐习惯于将流媒体视频传输到电视上观看。
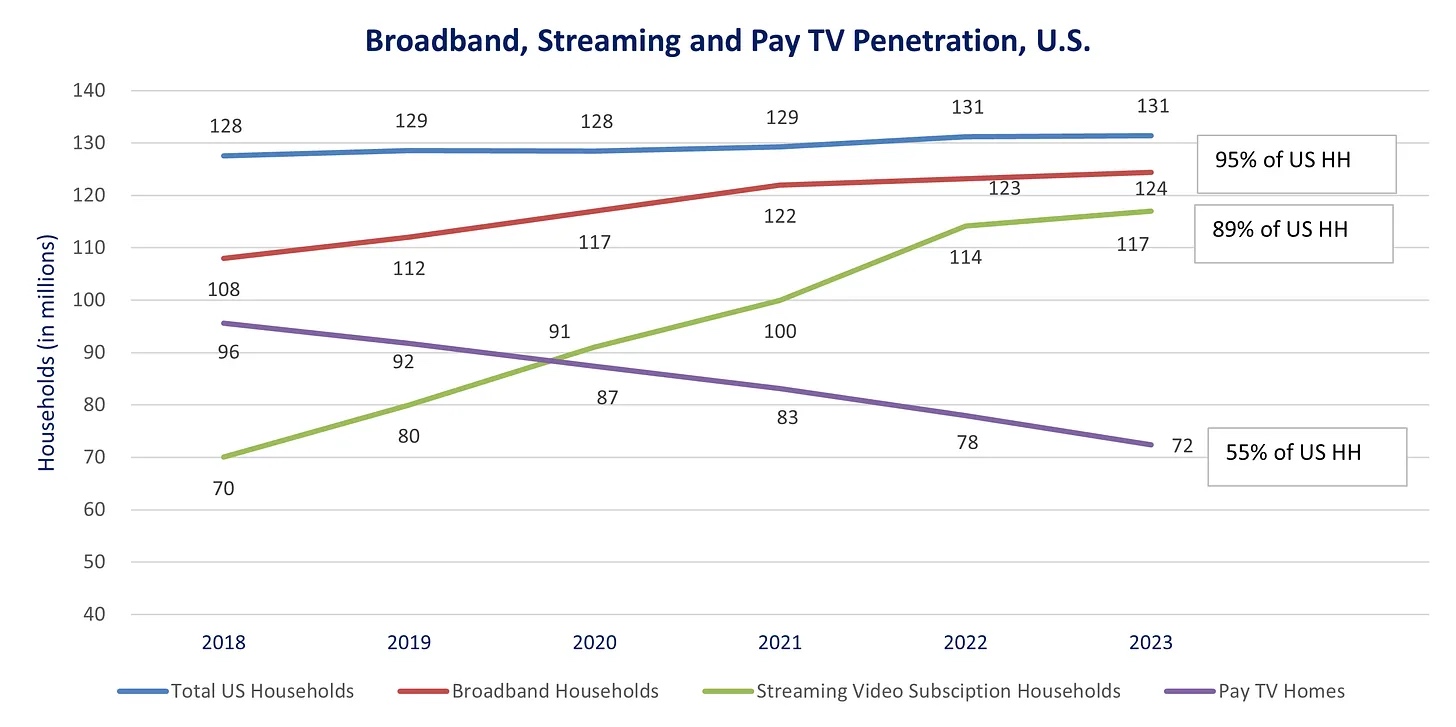
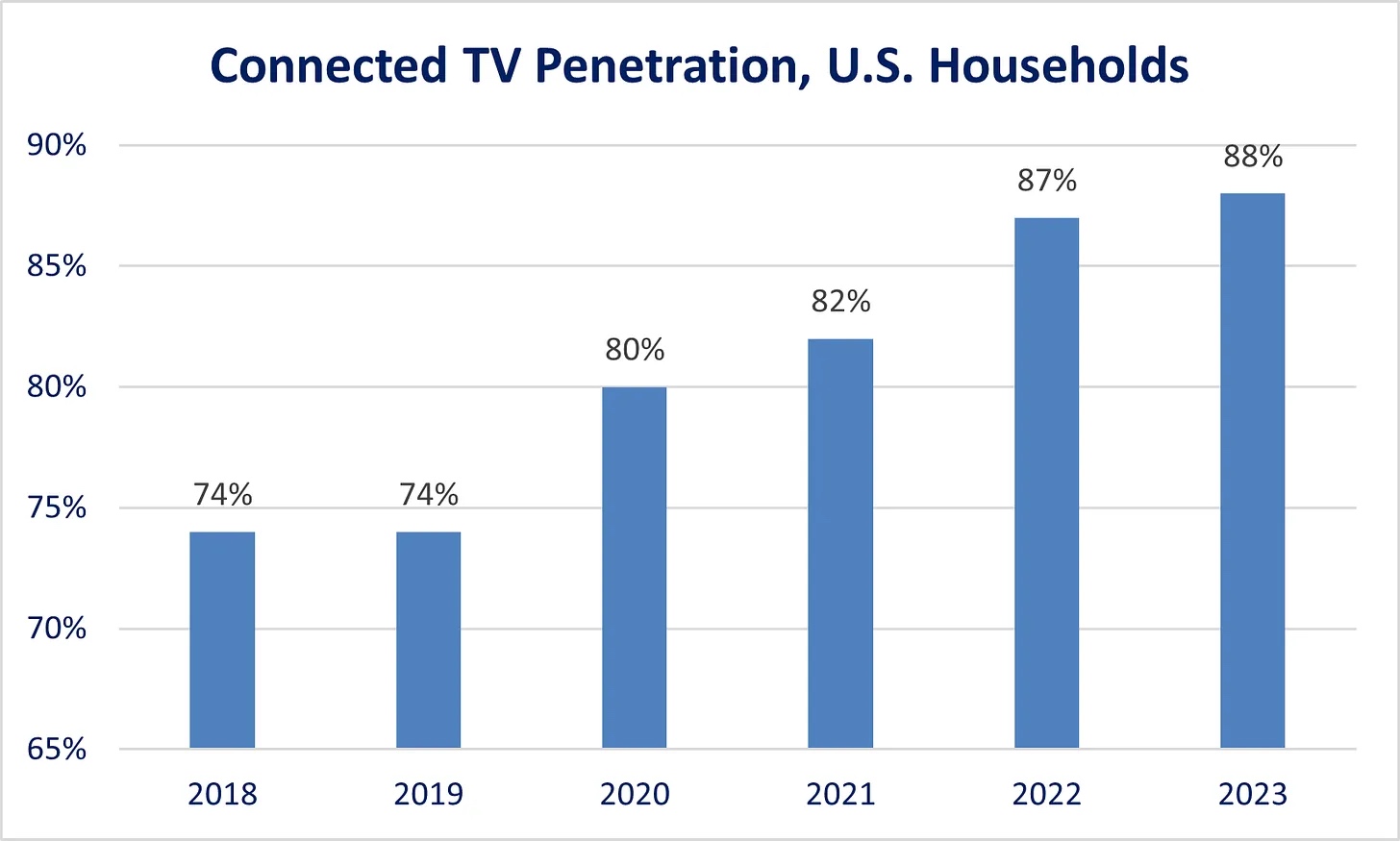
与此形成鲜明对比的是,如今所有这些条件已经成熟。如图 2 所示,YouTube 已经成为面向电视的第一大流媒体服务平台;而如图 6 所示,近 90%的美国家庭至少订阅了一项流媒体服务;如图 7 所示,联网电视在美国的普及率也接近 90%。如果有精彩的虚构剧集或喜剧出现在 YouTube 上,它完全有可能在一夜之间成为美国最受欢迎的节目。
X2V 模型的发展现状
不言而喻,X2V 模型与 Midjourney 和 DALL-E 等 T2I(文本转图像)模型密切相关。T2I 模型生成单张静态图像,而 X2V 模型则生成一系列连续图像,当这些图像快速连续播放时(标准为每秒 24 帧),就能够模拟出动态效果。我们可以将 X2V 模型视为更复杂、高级的 T2I 模型版本,或者将 T2I 模型视为只输出一帧画面的特殊化 X2V 模型。
因此,从 AI 图像生成开始探讨是一个不错的选择。在过去的一年里,T2I 模型取得了令人惊叹的进步,正如一篇关于 Midjourney 的文章所强调的那样。以下展示了两组图片,对比了从 V1 版到 V6 版在大约一年内的改进情况。到了 V6 版,几乎无法区分生成的图像与真实照片之间的差别。


即使在 Sora 诞生之前,X2V 模型也已经以惊人的速度不断进步。请参考以下两个视频示例。其中,“Pepperoni Hug Spot”广告短片发布于 2023 年 4 月,“The Cold Call”短片则发布于同年 11 月,两者均使用了 Runway Gen-2 技术制作,仅仅相隔七个月的时间差。
第一个视频是一个令人不安、如同梦呓的商业广告。第二个视频质量则有了显著提升,但仍然凸显了当前 X2V 模型的一些局限性:
分辨率:分辨率已经有了很大的改进,Runway Gen-2 能够生成 1080p(1920 x 1080 像素)的输出,但与拍摄 4K(3840 x 2160)或更高清晰度的电影级摄影机相比仍有差距。
时间一致性:在连续帧之间,物体、人物、光照和色彩可能会有不一致的变化。
时间连贯性和真实物理效果:目前市面上可获得的商用 X2V 模型,在动态表现方面存在较大问题,比如人、动物、车辆自然的运动状态,以及更复杂的相互作用如流体动力学等。在 “The Cold Call” 中可以观察到,汽车移动或人物行走时动作尚显生硬。
视频长度:由于较高的计算强度,保持帧间一致性的挑战,以及生成多帧图像所需的内存压力,大多数 X2V 模型输出的视频长度受限,通常只能生成几秒钟的内容(Pika 1.0 版本限制为三秒,而 Runway Gen-2 可以达到最多 18 秒)。
人类语音同步及情感表达范围:现阶段,没有任何一款商用 T2V 模型能够实现音频与口型的准确同步,并且难以捕捉到表情细微变化的微妙之处。在 “The Cold Call” 中,Uncanny Harry 可能使用像 D_ID 这样的工具将角色的嘴型动作动画化。
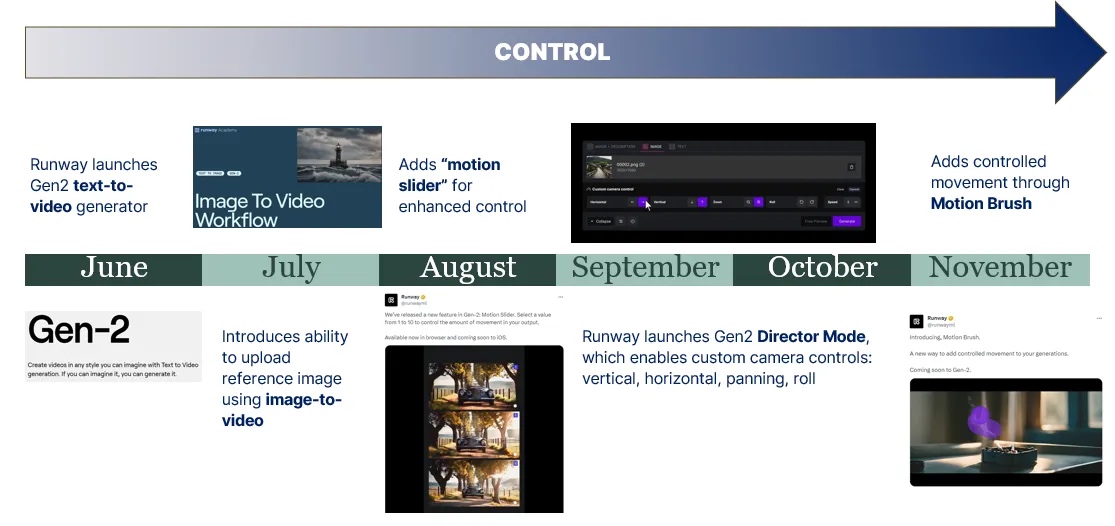
创作者控制力:尽管 T2V 模型逐渐增加了更多的创作者控制功能,例如 Runway 在去年晚些时候为 Gen-2 添加了 Director Mode 和 Motion Brush,使创作者能够调整摄像头角度和指定图像中的特定元素进行移动(参见图 9),但在大多数情况下,对 X2V 模型进行创意控制仍需要精细调整参考图像或参考视频,或者通过多次迭代不同的提示词这一既笨拙又成本高昂的过程来进行。
Sora 为何如此出色?
Sora 之所以令人震惊,是因为它在一次发布中就解决了许多上述局限性,尽管并非全部。
仅看这一段视频,其中女性角色的真实感、帧间一致性、动作的可信度、1 分钟的长度、街道及太阳镜的光线反射效果,都比市面上现有的模型有了显著提升。
提示词:“一位时尚女性走在东京街头,街道充满了温暖的霓虹灯和动态的城市标识。她身穿黑色皮夹克、红色长裙和黑色靴子,手提黑色手袋,戴着墨镜和涂着红色口红。她自信而随意地走着。街道湿润且有反光效果,形成了五彩灯光的镜面效果。周围有许多行人穿梭”(来源:OpenAI)
Sora 的技术论文可以在 这里 找到。我不能声称完全理解整篇论文,但以下是我作为一个非专业人士对 Sora 相较于其他 X2V 模型所实现的主要创新之处的理解:
- 通过使用“时空补丁”技术,Sora 将 Transformer 模型与 Diffusion 模型相结合。 Sora 是一种 Diffusion Transformer 模型,理解这一点需要对 Diffusion 模型和 Transformer 模型的工作原理有高级别的认识。
Diffusion 模型 是大多数图像和视频生成模型的基础。其基本思想是,从图像开始,通过逐步向图像添加噪声来进行训练,然后学习这个过程的逆操作,即去除噪声以生成清晰可识别的图像。在文本转图像生成器的情况下,模型还必须在文本-图像对或标题上(text-image pairs, or captions)进行训练。
为了生成新图像,模型接收到文本提示词后,首先将文本编码以便理解其含义,接着从一个高噪声图像开始,逐步去除噪声。在整个去噪过程中,它会利用已编码的文本作为指导,迭代生成相关图像。
Transformer(如 OpenAI 的 GPT 系列、谷歌 Gemini、Meta 的 Llama 系列,或 Mistral 等开源模型)背后的关楗创新。在 Transformer 模型中,原子单位是“令牌”(token)。
简单来说,大语言模型将文本(单词、词组组成部分甚至标点符号)转换为令牌,然后赋予这些令牌唯一的多维向量值(这一过程称为嵌入)。例如,GPT-3 为每个令牌分配 2048 个维度,每个维度都是离散值。之后,它们通过大规模数据确定这些令牌之间的语义关系,并基于每个令牌的重要性(通过所谓的“注意力机制”[3])分配权重。经过训练过程,模型会细化每个令牌的向量值。举个粗糙的例子,“教师”的向量值可能接近“学校”或“学生”,而远离“金橘”。
虽然 LLMs 中的令牌是文本,但在 Sora 中,令牌则是视频的“时空补丁”(spacetime patches)。首先,模型将视频分割成补丁,这些补丁是视频帧随时间变化的组成部分(因此称作“时空”)。然后,这些补丁像 LLMs 一样被转换为令牌,并运行类似的训练过程(这次是在大规模视频而非大规模文本上)。这使得模型能够理解补丁之间在时空上的微妙语义关系。这些补丁还通过文本-补丁对(text-patch pairs)关联到相应的文本信息。
Sora 结合了 Diffusion 模型和 Transformer 模型的概念,从高噪声的补丁开始,在文本提示词的指导下运行扩散过程,最终得到“干净”的补丁。尽管帮助不大,但以下是 OpenAI 提供的可视化表示(图 10)。
这种方法似乎是实现流畅且逼真的运动效果,以及帧间角色/物体/光照/色彩一致性的关键所在。
- 压缩。 之前我跳过了这一部分,但在作为令牌嵌入之前,时空补丁会先经过压缩处理(可能采用与数字视频几十年来相同的压缩方式,即仅保留帧间或补丁间变化的信息)。扩散过程同样从高噪声的压缩补丁开始,在得到干净的补丁后进行上采样以生成视频。
这种压缩在计算效率上更高,并且很可能是模型能够输出更长时长视频的关键原因之一。
- 利用 GPT 技术。 OpenAI 在自然语言处理(NLP)领域处于领先地位,这无疑为其提供了更好的优势去理解文本提示词中的细微差别。论文中还提到,Sora 利用 GPT 来扩展用户提供的简短提示词,并添加缺乏的详细信息。
对语言更细腻的理解使得 Sora 更好地理解用户的意图,从而提高了输出结果的相关性。
Sora 盖过了近期其他多项进展
尽管 Sora 在人工智能领域一枝独秀,但最近几周,来自谷歌、字节跳动和英伟达等公司的 X2V 技术也取得了一系列突破性发展。
Lumiere: 上个月,谷歌宣布了名为 Lumiere 的技术,它与 Sora 类似,目前尚未商业化。如下面视频所示,它也能生成比市面上已有的 X2V 模型更加自然流畅的运动效果。其主要突破在于一次性创建所有关键帧(视频中最重要的帧),而不同于其他模型按顺序生成关键帧,然后再填充关键帧之间的帧。这种对整个视频更为全面的理解使它能够呈现出更自然的过渡效果。
Boximator: 上周,字节跳动的一组研究人员发布了 Boximator,这是一个针对现有视频 Diffusion 模型的插件。如下所示,Boximator 赋予创作者通过绘制方框来标识特定视频元素,并指导它们如何移动的能力。
ConsiStory: 两周前,英伟达宣布了 ConsiStory,这是一种在 Stable Diffusion Video 模型中保持帧间角色一致性的方法。基本思想是,模型识别出主体并通过“共享注意力块”(shared attention block)——基于 Transformer 模型中使用的注意力机制扩展而成的模块——确保主体(或多个主体)在帧间保持一致性。

Sora 的核心启示:视频是一个可解决的问题
Sora 并不完美,其生成的运动效果有时可能略显生硬甚至违背物理规律,同时它目前还未发布,我们尚不清楚其渲染视频所需的时间与成本,以及除了提示词本身之外,OpenAI 将提供何种程度的创作者控制功能。但相较于其他 X2V 模型,Sora 表明:视频问题是可以被解决的。
一年多以前,在 《告别电视黄金时代,迎接无限电视的时代》 一文中,我曾解释过为什么 AI 视频技术可能会迅速进步:
这些技术的发展主要受限于……算法的复杂性、数据集大小和计算能力——所有这些都是有可能快速进步的因素……
再次引用上述对比:在视频分发领域的颠覆过程中,需要挖掘大量土地、铺设光纤和建造发射塔;而 AI 视频技术的进步则无需任何这类实体设施的建设。
尽管理论上可能发展很快,但并不代表颠覆一定会如此发生。在 Sora 出现之前,人们认为 AI 视频可能会遇到某种技术瓶颈,这也是可以想象的。并非所有的 AI 问题都必然有解。由于我们尚未真正理解人类智能的基础,所以也许我们永远无法实现通用人工智能(AGI)。或许我们永远无法拥有真正的“5 级”自动驾驶,因为我们不愿接受(不可避免地存在的)非零风险,即自动驾驶车辆有时会致人死亡。然而,Sora 的成功表明,视频这一问题至少是能够找到解决方案的。
视频并非通用智能,也不存在生命安全风险,因此其标准和牵涉的利益相对较低。毕竟,视频本质上是一种错觉,它不是现实,而是每秒 24 帧的静止图像,让我们误以为看到的是动态影像。对于任何虚构的影视作品,我们也明白所见并非真实。X2V 技术只需要足够好,使我们暂时忘却怀疑并沉浸于故事之中就可以了。Sora 展示出 X2V 很可能在不久的将来跨越这一门槛,原因有三:
开源开发。 AI 在某种程度上是独特的,因为它的发展很大程度上是在公共领域进行的,即使是由私营公司推动的进步也是如此。(例如,支撑 OpenAI 的核心创新,源于谷歌率先提出的 Transformer 架构。)这可能是因为许多 AI 研究的根源在学术界,人们相信开源有利于公益并加速发展,或者由于处于前沿所带来的公关优势。无论原因为何,大量研究成果公开发布的趋势显然正在加快创新的步伐。
组合性。 基于上述观点,尽管 Sora 的技术论文并未完全揭示底层架构和模型的秘密所在,但其众多引用清楚表明它建立在许多先前进展的基础之上。这些进展包括但不限于 Transformer Diffusion 模型的概念、时空补丁技术、Diffusion 模型的改进,以及文本条件化(text conditioning)的进步。在软件领域,能够像乐高积木一样组合使用多种不同工具和模型的能力被称为“组合性(composability)”。许多 AI 模型设计成模块化形式,以便用户轻松地与其他工具结合或使用。这也同样加快了创新的速度。
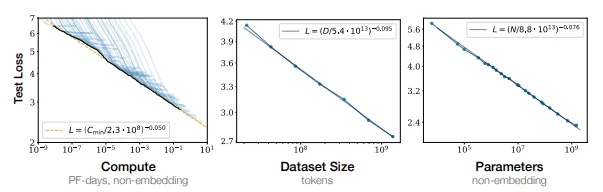
规模效应。 2020 年,OpenAI 的研究人员发表了一篇名为 《神经语言模型的规模定律》(Scaling Laws for Neural Language Models) 的论文,指出模型规模(scale)的重要性超过了模型架构本身。研究发现,LLM(大规模语言模型)的性能会随着训练数据集大小、参数数量(模型复杂度的衡量指标)以及计算能力的增加而平滑提升。如图 12 所示,每个变量的规模与其模型误差之间存在明显的无界逆幂律关系(unbounded inverse power law relationship)。换句话说,规模效益并无明显的上限。这一点在随附论文的视频中生动展现出来。图 13 展示了在不同计算级别下,一只戴着蓝色帽子在雪地里玩耍的狗的三个视频片段。
图 13:计算力提升带来的模型改进,顶部视频为“基础”计算级别,中间视频为 4 倍计算级别,底部视频为 32 倍计算级别(来源:OpenAI)
这三个因素——开源开发、组合性、不断增长的数据集与计算规模——表明了为什么 X2V 只会变得越来越好。
“神圣的觉醒时刻”
从上周所有的媒体报道来看,显然 Sora 对许多人来说是一次重要的警醒。其中最生动的例子可能是 Tyler Perry 决定停止其制作设施的扩建。
一年前还停留在理论层面的东西,如今每周都在变得愈发具象化。这些工具可能只会不断进步,因此在未来几年中,“高质量”内容的数量可能会大幅增加。对于价值链中的每个人来说,面临的挑战是一致的:(1)接纳并利用这些工具;(2)确定它们如何帮助你更好地完成工作;(3)探究当质量趋于无限时,什么会变得稀缺,这是我 最近在这里所写的内容。
- 1.Mr. Beast 经营着几个其他的 YouTube 频道,包括 Mr. Beast 2、Mr. Beast 3、Mr. Beast Gaming 和 Beast Reacts。 ↩
- 2.当使用斜体时,Mr. Beast 代表上传到 Mr. Beast 主频道的所有视频。 ↩
- 3.注意力机制的重要性体现在,Google Deepmind 首次提出 Transformer 架构的开创性论文标题为《注意力就是你所需要的》。 ↩
转载请注明来源。欢迎留言评论,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。