由 Filmlight 公司的色彩科学专家理查德·柯克(Richard Kirk)撰写的色彩科学白皮书《颜色:感知与测量》(Colour: Sense & Measurement)第一章(翻译初稿)
译者:Horace Lu
原书下载地址
理解视觉这一概念并非易事。简单的解释可能会将人眼类比为摄影机,把大脑类比为计算机,并讨论“电磁辐射”(electromagnetic radiation)和“可见光谱”(visible spectrum)等概念。但这种解释是错误的:“看见”并不仅仅是对光线的检测,它涵盖了从感知刺激到理解信息的整个过程。这个复杂的过程有很多知识需要理解,也有很多知识尚待探寻。在我们开始攀登这座认知的高峰之前,让我们先远观其轮廓,寻找一条通往顶峰的安全路径……
《脑中小人》
在我小时候,有一本名叫《The Beezer》的漫画杂志(每周四出版,售价 4 便士),上面刊登了一组名叫《脑中小人》(The Numskulls)的连环画,讲述了在人脑中生活的一群小人的故事。

每个“脑中小人”都有自己的位置和职责,但也可以在头脑中自由走动。在紧急情况下,一个小人可以接替另一个小人的工作。漫画的大部分故事情节都发生在人脑内部,但漫画的最后一格通常会从外部展示这个人,用气泡揭示他的想法,这些想法和他脑中每个小人的行为都被描绘得栩栩如生。虽然故事内容比较简单,但这个概念非常精彩。
经颅磁刺激(TMS)
最初,通过观察那些在头部的某个局部受伤后失去特定技能的人,我们得了解大脑各部位负责的功能。在现代科学中,对应的更加人道的研究方法是经颅磁刺激(Transcranial Magnetic Stimulation, TMS)。TMS 可以利用突变的磁场,暂时激活或抑制大脑内的一些小区域。如果将 TMS 设备对准你头部的特定部位,你就可能会暂时失去识别颜色、辨认表情或理解字母的能力。刺激其他部位则会使你做出一些身体动作,比如自动抬起一只手臂。当这种情况发生时,你不会觉得手臂是被别人强行拉起来的,而是会产生“我自己想这样做”的感受(来自亲历者的描述)。借助 TMS,我们可以更精确地了解大脑各个特定区域的功能。
意识的所在地?
假设大脑中每个部位仅执行机械式的信息处理,这种想法似乎很有吸引力。如果真是这样,那么实际的思考过程发生在哪里呢?在大脑中是否有一个中央处理单元,接收所有部位的汇报?如果对物体颜色、形状、运动和其他属性的识别发生在大脑的不同部位,那么这些信号是如何汇集在一起,形成一种统一认知的呢?
在大脑中并没有一个明确的“意识所在地”。笛卡尔认为,意识是非物质的灵魂,通过松果体与物质的大脑进行交流。我们也可以仿照笛卡尔提出假设:意识存在于可见的形体之外,或是存在于一个我们尚未发现的物理位置。然而,这两种假设都无法真正解释任何事情,它们只是推迟了于意识本质的探讨。话虽如此,“信号处理与信号理解之间存在明显界限”,这样的观点在普通人和专家之中都还是很有市场。在著作《意识的解释》(Consciousness Explained,1991)中,丹尼尔·丹内特(Daniel Dennett)将这一观点比喻为,想象在我们的大脑中有一个负责思考的小人(homunculus),或是有一个独立思考的小脑。这就像是“缸中大脑”的思维难题(“你怎么知道你不是一个缸中的大脑,你所经历的世界全都是模拟出来的?”),只不过是将其内外翻转了一下。这种思路也很有趣,但同样并未提供任何实质性解释。一个更好的,并且可以证明或证伪的假设是:意识分布在我们所能观察到的大脑各个部位当中。一个蚁群可以很聪明,但一只蚂蚁作为个体却很笨拙。人类的意识来自于其“脑内小人”的行为,但其思想并不属于任何一个单独的“脑内小人”。
混沌架构
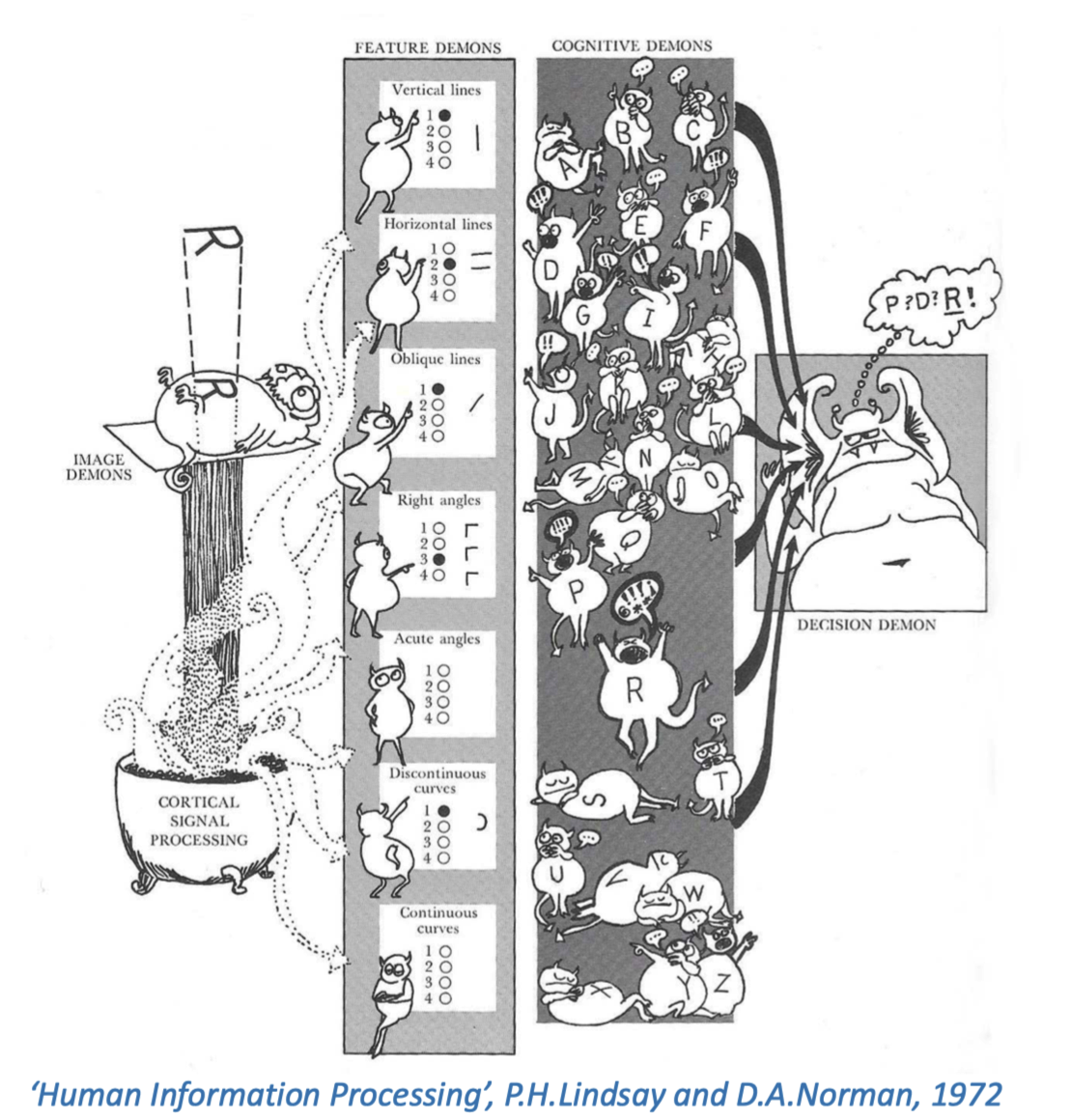
我们对脑内小生物的讨论还没结束。混沌架构(Pandemonium Architecture)是一个低层次的模型,用来描绘我们如何解读视觉细胞感知的信号。这个模型由很多执行简单专门任务的“小恶魔”(demons)组成,每个“小恶魔”可能由几个神经细胞构成。它们没有自我意识,也不像模型所暗示的的那样有明显的区别。尽管如此,把思维过程用各司其职的“小恶魔”来描述,有助于解释我们的视觉可能是怎样工作的。
第一层“小恶魔”通过皮层信号处理(cortical signal processing),将原始图像转换为信号,这一层并未详细展示。第二层“小恶魔”负责识别可能属于字母的显著特征,如果找到了就发出声音。第三层“小恶魔”聆听第二层的声音,如果听到的内容与它们负责的特定字母相匹配,则它们也会发出声音。最后,负责决策的“小恶魔”聆听第三层哪个恶魔叫得最响,并选择对应的字母。
学习观看
你可能并不是以上述方式阅读这段文字的。刚开始学习阅读的人,首先会将字母作为单独的符号进行识别,但很快就能通过形状来识别短序列,随后根据前文预测接下来的内容。
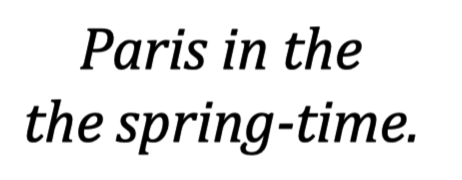
这一点可以通过我们常犯的错误来证实。一个正在学习阅读的人可能会注意到上图中多了一个 “the”,但一个成年人可能就不会注意到。然而,“混沌架构”解释了我们为什么会犯特定的错误,同时也为如何构建一个强大的字符识别程序提供了建议。人工智能也已经向我们展示,这种简单的模型能够做到很多事情。
还有另外一个顽固的观点反复出现,那就是:视觉仅仅是一个自下而上的过程,信息只从较低级、原始的层次,单向流动到更高级、复杂的层次,并最终形成理解。但实际上,信息的反向流动也是必须存在的,只有这样,负责分辨“R”的恶魔才能知道要寻找哪些特征。如果没有这种反向流动,那我们生下来就应该会识字才是。事实上我们连怎么“看”也是要学习的。从出生起就患有白内障的人,在手术后并不能突然看见东西,而是要逐渐学习这一过程。大多数人在看东西时都会使用大脑的相似区域,所以似乎是大脑的架构在指导着这个学习过程。但我们每个人都有自己独特的看到事物的方式。
一个简单的场景
让我们从理论转向实际,来看看一些颜色。下面的圆是什么颜色?
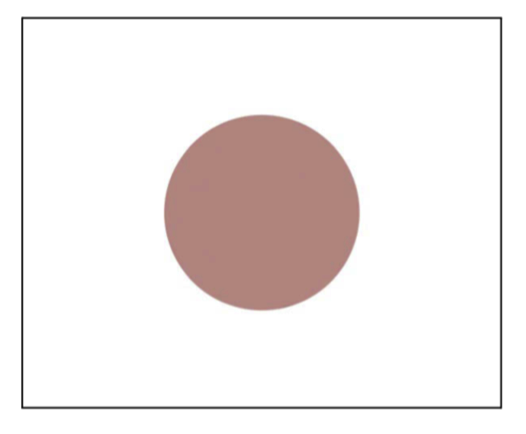
我看到的是像医用创可贴那样的粉灰色(pinkish-grey),并不像是任何人的肤色。也许周围的白色让我们分心了,换成黑色背景试试看。

看起来区别不大。也许因为黑色周围环境(surround)的存在,粉色看上去更亮了一点。让我们在黑色背景下看看原始的物体是怎样的。

颜色忽然看起来不一样了。我们知道这个物体是枚一便士的硬币(或至少是一枚小硬币),它的颜色是黄铜色(copper coloured)的。新鲜的铜是亮粉色(bright pink)的,随着氧化会变成棕色(brown)。在这张图中,它看起来很有光泽,但也可能只是光照效果造成的。

现在让我们把硬币放在一个简单的真实场景中。背景提供的线索不多,但在另一枚硬币的衬托下,原来那枚显得很有光泽,虽然上面的日期告诉我们它已经有二十多年的历史了。
我们最初用黑色背景替换了白色背景,效果并没有什么不同。但黑白排列方式的不同确实会产生很大差别。在下图中,把相同的粉褐色(pinkish-brown)排列在黑白相间的条纹中,这种排列方式称为怀特错觉(White’s illusion)。所有粉褐色(pinkish-brown)斑块的颜色都是相同的,但左侧斑块看起来像是氧化后的硬币,右侧斑块看起来则像是有光泽的那枚硬币。

在左侧,我们透过黑色条纹看到了白色背景下的颜色。在右侧,我们透过白色条纹看到了黑色背景下的颜色。在观察圆形时,背景的改变并没有产生太大差异,但在这种图案下,效果却明显不同。[1]
周围环境的效果
我们看到,相同的颜色刺激在不同的周围环境(surround)中呈现出不同的颜色效果。假设我们去掉周围环境,让整个视野都被同一种颜色所填充,这样做是否有助于展现出这种颜色的 实际 样貌呢?如果把整面墙或天花板都涂成上面的颜色,它看起来可能会比原始的颜色样本更亮、更偏粉(pinker)。这一点我很清楚,因为我的父亲在我成长的家里正是这样做的,而且不止一次。油漆罐里的油漆与颜色样本是一致的,但在观察一个大面积、无特征的颜色块时,我们的周边视觉(pheripheral vision)也会参与进来,而周边视觉看到的颜色与中心视觉(central vision)略有不同。然而,如果把一块小的颜色样本放在涂过的墙边,它们的颜色看起来又是一致的。
几年前,当液晶设备(Liquid Crystal Device, LCD)显示器与阴极射线管(Cathode Ray Tubes, CRT)显示器开始并排用于图像校色时,我们也观察到了类似的现象。你可以尝试用校色仪器校准两个计算机显示器。在两个显示器上显示一个相同的小色块时,颜色看起来是一致的。但当你在全屏显示白色时,LCD 屏幕相比 CRT 屏幕会看起来略偏橙色。这种橙色虽然不明显,但足以让从事色彩工作的人感到担忧。在观看小色块时,我们主要使用中心视觉。而在观看整个屏幕时,我们会同时用到周边视觉。在日常生活中我们很少注意到这一点,但在某些情况下它却很重要。
我们可以从中得出的另一个结论是,人的眼睛和大脑完全不能用摄影机和计算机来类比。每台显示器各自显示全屏颜色与小色块是一致的,两台显示器的小色块之间也是一致的,所以按理说,两个全屏显示的颜色也应该是一致的,对吧?但实际上并非如此。这是一个悖论!如果我们在两个显示器上显示一幅图像而非单一色块,则会在一定程度上掩盖这种差异:尽管我们看到的每种颜色似乎都是一致的,但我们可能仍然有一种隐约的感觉,那就是整体的色彩平衡似乎是有问题的。在使用计算机显示器与胶片进行匹配时,也会遇到同样的情况。
物体形状的效果
看来没有一个场景能完全展示出颜色的 真实 样貌。然而,我们可以将一小块纯色图案,置于大面积的黑色周围环境(surround)下进行观察。如果这个色块约与伸直手臂时拇指的大小相当,它就匹配了我们用于精确视觉(precision vision)的眼睛中心区域。

不过,这个形状不太合适。它看起来像一只手,这可能会使我们联想到肉色(flesh colours),影响我们对颜色的解释。Gegenfurtner 教授及其团队的研究显示,形似水果和蔬菜的色块会显著影响我们对其颜色的感知,使我们识别出的颜色强烈地偏向或背离这个形状所预期的颜色。我们可以用圆形作为参考形状,因为圆形是相对中性的。如果以香蕉形状代替圆形,则接近黄色的色调看起来会更黄,而灰色会看起来更蓝(黄色成分减少)。这也适用于其他水果形状。一串葡萄的形状会产生两种截然不同的效果,这取决于观看者联想到的是绿葡萄还是紫葡萄。
2 度标准观察者
“2 度标准观察者”(2-degree Standard Observer)在很多视觉实验中都有应用。

观察者看到的是一个置于大面积黑色周围环境下的彩色圆形。这个圆可能会被分成两个半圆,用于比较两种颜色。在观看时,圆形在观察者眼中占据 2 度视角,大致相当于伸直手臂时的拇指大小。黑色的周围环境不必完全没有光,只要远比刺激物暗就行。这种布局同样无法展现出颜色的 真实 样貌,可能没有任何一种布局能精准表达颜色的实际样貌。但通过 2 度标准观察者,我们可以观看任何给定的颜色,或判断两种颜色是否看起来相同,并得到前后一致的反应。
上图展示的两种颜色可能看起来像上文中怀特错觉的粉色。右边是原始颜色,左边是一个稍暗的版本。然而,如果从怀特错觉的图片中把实际的颜色提取出来,会发现它们是匹配的,因为它们本身就是同一种颜色。
2 度视角之所以效果很好,是因为它是我们中央视觉区域的大小,我们大部分的精细视觉都依赖于这个区域。当我们观看一个 2 度的圆形时,我们的目光会自然地集中在其上。如果用一个 10 度的圆形将周边视觉也涵盖进来,那么我们的目光就会在圆内游移,难以获得前后一致的反应。

这里我们展示的是放在渐变背景上的一系列纯色的灰色方块。每行方块的颜色都完全一致,但在深色背景下它们显得更亮,在浅色背景下则显得更暗。即便是对于 2 度观察者来说,周围环境的影响依然是很显著的。我们选择黑色作为 2 度观察者的标准背景,因为每个人对黑色的认知都相同,尽管这种黑色可能比我们在实际场景中看到这些颜色的背景更暗。
2 度观察者的视角非常简单,以至于几乎没有发生真正的“观察”(seeing,注:指的是本章开头的看到并理解的过程)。这一点非常有用,它使我们可以测试两种颜色是否能引发相同的反应,同时避免了周围细节产生的干扰。我们用这样的视角来说明,我们的眼睛在正常颜色视觉中采用三种传感器;推测这些传感器对哪些颜色的光产生反应;并探究这些传感器的反应在不同人群中是否相同。我们将在下一章更深入地探讨光刺激及其测量方式。
棋盘阴影错觉
现在,让我们来看一张包含可辨识物体的图片。
这是麻省理工学院(MIT)的 Adelson 教授于 1995 年发布的一张著名的错觉图片。
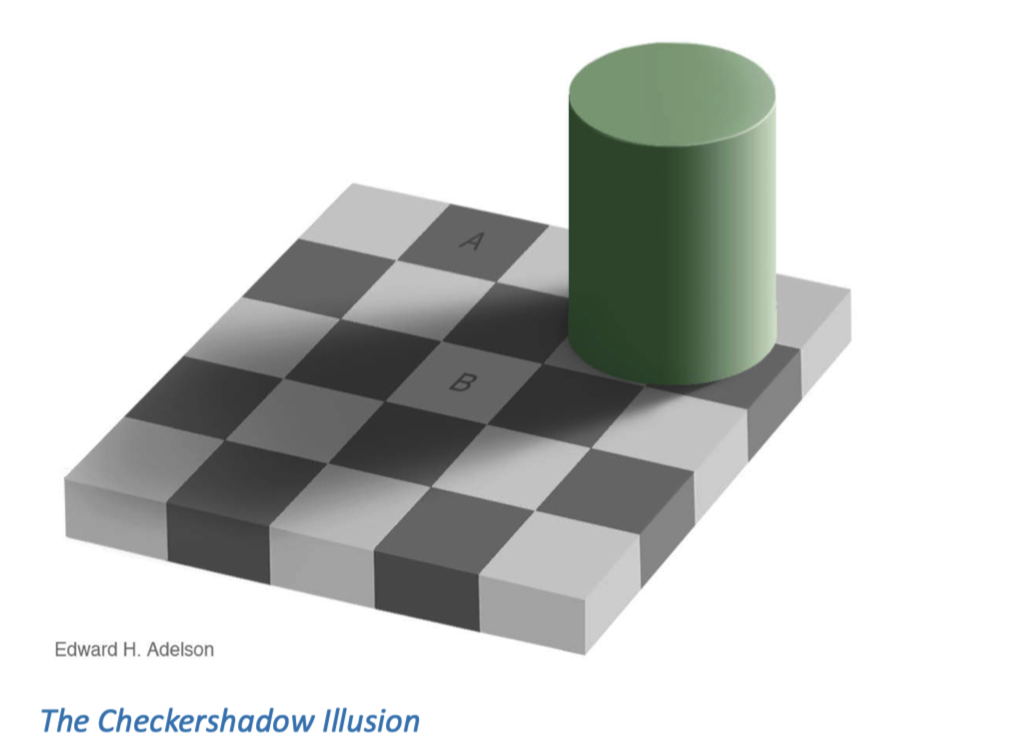
图中标有 A 和 B 的两个方块实际上颜色相同。如果把 A 和 B 的灰色放到 2 度观察者目标的两个半圆中,我们是看不出分界线的。然而我们却看到它们的灰度有明显的区别。我们可能会这样写下看到的情况:
- 有一个双色调(two-tone)的国际象棋棋盘。在我们的预期中,所有的浅色方块都是一样的,所有的深色方块也是一样的。
- 有一个绿色的物体,从形状来看是一个圆柱体。阴影进一步证实这是一个圆柱体,而且光线来自右上方。棋盘格两侧的阴影也支持这一点。
- 绿色圆柱体显然在棋盘格表面投下了柔和的阴影。
- 方块 A 是一个在亮处的黑色方块,而方块 B 是一个在阴影中的白色方块。
“看见”并不是一个简单的自下而上的过程,而是多个过程同时进行。我们从光影中猜测出三维形状,又从三维形状中推测出光源位置。我们可能在意识到有影子之前就分辨出了棋盘图案。我们可能知道有影子的存在,但通常会忽略它,因为我们更倾向于识别物体,而不是欣赏光影的变化。
我们当中更有经验的人会知道这是一个错觉,并可能会猜测 A 和 B 的颜色应该是相同的,因为这正是错觉的特点。但它们看起来依然是那么不同。
在这一点上,让我们思考一下在描述棋盘阴影错觉(Checkershadow illusion)当中的 A 和 B 色块时,我们是如何用词的。在这里描述得严谨一些,可能会对我们后面的理解有所帮助。
我可能会说,A 看起来 比 B 更暗。在这里,我描述的是这两种颜色在特定环境中对我而言的外观。或者我可以说,A 看起来是 深灰色(dark grey),而 B 看起来是 浅灰色(light grey)。更严格地讲,我可以说 A 对我来说 看起来是深灰色,而 B 对我来说 看起来是浅灰色,由此强调你可能跟我有不同的感受……

著名的“连衣裙”照片是一个罕见的例子,人们对此看法迥异。这条连衣裙实际上是蓝黑色的(blue and black),但我总觉得它是蓝白色(blueish-white)和金色(gold)的。
假设我说 A 和 B 是同一种颜色,或 A 和 B 相 匹配(matched)。如果 A 和 B 都印在纸上,我可能会通过剪下这两个区域并把它们贴在一起来证明这一点。我或许会在单一的黑色背景下展示它们,以消除周围图像的影响。我甚至可以把 A 和 B 裁剪成适合 2 度标准观察者的圆形,这样我就可以说,A 和 B 在 2 度标准观察者的观察条件下相匹配。
最后这句话可能看起来有些吹毛求疵:如果我们在把 A 和 B 并排放置时时看不到反差(contrast),那么它们一定匹配,对吗?然而,如果 A 和 B 是需要匹配的两种不同材料,我们可能会把它们放在日光和人造光线下分别检查。2 度的视角大小也很重要,就像我们讨论过的刷墙的例子,以及在显示器上比较白色的例子。
当我说 A 和 B 是相同的颜色(are the same colour) 时,意味着它们在所有可见波长下具有相同的视亮度(brightness)。如果 A 和 B 是反射色,那么它们在所有可见波长下反射相同比例的光,且在同一光源下观察时会匹配。它们在各方面的颜色完全相同,对于测量仪器或是具有非标准视力的人而言,它们也都是匹配的。
当我说 A 和 B 匹配(match) 时,指的是它们之间没有可见的反差(contrast),即使它们在所有可见光波长下的视亮度(brightness)不一定相同。这种说法是不完整的,因为我没有具体说明匹配条件,你应该根据上下文来理解匹配条件。
我说 A 和 B 在 2 度观察条件下对我而言是匹配的,如果它们在这些条件下对我来说确实是一样的。或者说,当我把它们剪下来并排放置时,A 和 B 对我来说是匹配的。
我说 A 和 B 根据 CIE 2006 标准 2 度观察者是匹配的,如果它们的测量光谱在这个特定标准下给出相同的值。这个标准使用一个测量仪器,通常是光谱仪(spectrometer)而不是我的眼睛,同时使用人类色彩感知的物理模型。我在这里使用的标准,与一个视力良好的典型观察者在使用 2 度几何形状进行比色时的结果相匹配。CIE 1931 XYZ 2 度观察者是另一个较旧但仍广泛使用的标准。这些标准观察者的测量值并不完全适合你我的视觉,但已经足够接近了,因此很有用。
我说 A 看起来很像 B,或者 A 看起来 比 B 更暗,这就是它们对我而言的外观。我没有试图改变展示方式,也没有试图将这两个色块放在一起。
你可能不需要这些确切的定义。大多数人在描述颜色时并不会尝试做到这么严谨。但如果有人说 A 和 B 匹配,请问问他们,匹配条件是什么。
其他感官
让我们暂时离开视觉的话题,来聊聊味觉。你喜欢布鲁塞尔芽菜(Brussels sprouts)的味道吗?这是一种外观类似小卷心菜的蔬菜,味道独特且浓郁。它们可以在整个冬季采摘,因此在英国的传统圣诞晚餐中经常出现。如果你对这种芽菜并不熟悉,也可以想象一下其他事物,比如蓝纹奶酪,效果也一样。

假设我和你都吃了一棵布鲁塞尔芽菜。我们都尝到了芽菜的味道,对吗?或者更确切地说,我们通过我们的牙齿和唾液,以及整个复杂的进食和味觉机制,感受到了布鲁塞尔芽菜的味道。唾液是很重要的;我认识一些人,曾经暂时失去唾液功能,他们发现所有食物的味道都大不相同,通常会变得相当难吃。尽管如此,理论上我们可以追踪芽菜从放入口中到在我们味觉器官的细胞中产生化学刺激的整个物理和化学过程。
我们可以进一步探讨这个话题。我们也许可以测量细胞本身的反应。大多数人将香菜(又称香荽叶)的味道描述为一种香郁的柑橘类风味,但有一小部分人将其形容为“肥皂味”或“恶臭”。我闻不到麝香,尽管我能闻到大多数其他东西。你可以尝试向我描述它,但这些描述(如“汗味、“动物味”)对我来说毫无意义。我们知道存在基因变异,导致人们对香菜和麝香的看法不一。我们可以找出哪些化学物质在特定检测器中激发特定反应,由此可以绘制出所有可能的味觉和嗅觉范围。把研究范围限定在具有 “正常 “ 感官的人是最容易的,但如果能找到足够多具有特定异常的人,那么预测他们的感受也是可行的。这并非一种哲学上的幻想:人们已经做到了这一点,并成功制造和预测了“味觉错觉”和“嗅觉错觉”。
那么神经信号会发生什么变化呢?我们可以用电探针对信号在细胞间的传递进行追踪。在追踪了几个神经细胞的信号后,我们很快就会迷失方向,不再知道每个信号的含义。这些信号消失在我们交错的神经中,而味觉或嗅觉则出现在我们的意识中。当布鲁塞尔芽菜的味道出现时,它附带着我们所有的个人元数据,因为我们总是在圣诞节晚餐时吃这种芽菜,或者在学校不得不吃它们。
我并不是在说,任何我们共有的感觉背后都有一个共同的感受器(sensor),而任何差异都是经验造成的——并非完全如此。例如,我们并不都对香菜叶的味道有共识。如果我们有许多感受器,且其中一部分人的感受器有着共同的差别,那么就很可能存在一个共同的原因。如果原因在遗传方面,找起来应该比较容易。但也有可能我们中的一部分人有不同味觉的原因来自于其他方面。
现在让我们回到视觉和颜色的话题。人眼中有三种类型的视锥细胞,它们检测光线并将其转换为神经信号,这是我们颜色视觉的第一个阶段。我们可以测量每种类型的视锥细胞对每种波长的光的敏感度。我们还可以计算出在光进入眼睛的过程中,其他部分如黄斑染料(macular dye)和眼球晶状体(eye lens)对每种波长的光各吸收了多少。我们甚至可以超越标准的 2 度观察者模型,测量细胞在周边视觉中的反应。
视锥细胞在光线照射下激活(放电,fire),更多的曝光会使它们更频繁地激活。理论上,我们可以根据曝光预测视锥细胞的激活频率。但在实践中这是很困难的,因为激活频率还取决于其他因素,比如之前已经接受过的曝光程度。已经被高度曝光所漂白(bleach)的细胞,不会像未曝光的细胞那样频繁激活。此外,由于眼睛会移动,所以特定细胞可能不会始终指向场景的同一部分。
这些信号会传输到其他神经细胞。我们可以用电探针追踪信号,并使用光学相干断层扫描(optical coherence tomography,OCT)追踪神经连接。神经细胞的下一层级更加难以建模,因为每个信号都会被附近细胞的输出所改变。很快我们就失去了神经信号和视锥细胞曝光程度之间的显著关联。这些信号消失在无底洞里,而颜色的感觉出现在我们的意识中。如果我们看着一棵布鲁塞尔芽菜,它看起来会是绿色的,但会带上我们所有的个人修饰,因为我们总是在圣诞节晚餐时吃这种芽菜,或者在学校不得不吃它们。
到目前为止,我们看不到检测(detection)和意识(consciousness)之间的明显区别。解释(interpretation)过程可能是从两个神经细胞相遇时开始的。初级处理层可能相当机械化,有点类似于使用神经网络进行图像识别。这些网络可能有很多层,但用户可能不是从零开始训练整个系统,而是从预训练的通用特征检测初始层开始。然后他们可以训练最后几层用于识别人脸、自行车、水果,或任何正在寻找的东西。尽管如此,一部分特征识别和解释过程,在神经信号离开视网膜之前就已经开始了。如果我们假设这些解释过程完全是机械的,那么我们就又回到了“小人谬误”(homunculus fallacy)之中。[2]
我们可能已经认识到,在检测和意识之间没有明显的分界线,但在我们目前可以测量的范围内确实存在一个明显的界限。我们可以测量刺激味觉、视觉、触觉或其他感官的受体,但很难追踪和理解单个神经信号的意义。我们通常可以对触发原始检测细胞的外部因素进行测量和量化,并将这些因素称为 “刺激”。这个刺激会进入一个复杂的过程,信号在神经细胞之间传递。这便是“脑中小人”(Numskulls)生活和存在的地方,意识通过这种方式获得对所尝、所见、所感的认知。
颜色恒常性
我们理解所见事物的这个“复杂过程”并非完全神秘不可知。理论上我们可以对任何特定的细胞进行建模。我们可以用经颅磁刺激(TMS)等工具进行实验,观察更大规模上发生的事情——我们在 这里 解释深度和立体感,在 这里 识别面部和表情,等等。即使我们无法直接测量意识,我们也可以增进对于这些机械处理过程的了解。举个例子:即使照明发生变化,我们通常也能一致地识别物体和它们的颜色。即使无法直接看到光源,我们也能做到这一点。这样的技巧(trick)是棋盘格阴影错觉发挥作用的原因,我们称之为颜色恒常性(color consistency)。用彩色摄影机和计算机来比喻的话,摄影机测量绝对的 RGB 值,而计算机会对这些原始值进行缩放(scale),以补偿和纠正对于照明光源白色(lighting white)的估计。我们的眼睛和大脑可能在视锥细胞输出信号前就无法准确测量曝光绝对值了,但它们仍然设法完成了同样的工作,而且做得相当好。
颜色恒常性也取决于我们所观察的对象的实际展示情况,其中包括:
- 简单的带颜色的形状,带有周围环境。
- 简单的海报形状的图像,具有平坦的色彩。
- 带阴影的图像,看起来像是一个场景的视图。
- 可能被误认为是场景照片的图像。
- 沉浸式环境,以及真实的场景。
当我们观察简单形状时,周围颜色对我们颜色感知的影响可能是较弱的。而在观察更复杂的图像时,颜色恒常性会变得更强。在上述列表中,棋盘阴影错觉属于第 3 类:我们不会认为它是一个真实的场景,但会根据明显的光影线索进行解读。我会把“那条裙子”的照片归为第 4 类:它是一个真实场景裁剪后的照片,但也可能是作为一种错觉来构造的。我们在这里遵循的是不明显(non-obvious)的光照线索,并在接近完全的颜色恒常性作用下犯了错误。由此可见,我们需要一个真实的图像(来引发颜色恒常性),但不必相信我们在看的是一个真实场景。颜色恒常性不是在视网膜上发生的,它需要对整个图像进行深层解读。
在我们能够理解包括意识在内的整个系统之前,我可以提出以下观点:
- 我们需要识别事物。即使光线变化或存在多个光源,我们也不应该感到困惑。
- 我们可以模拟光照如何影响摄影机“看到”的内容,并对其进行校正。
- 我们猜测,眼睛和大脑需要实现相同的目标,并且实现手段必须与数字摄影机完全不同。但如果我们理解了摄影机的校正过程,我们也可以类似地模拟眼睛和大脑的工作过程。
这并不是一种很好的推理。人们还提出了以下观点:
- 旧世界的猴子具有双通道色觉。
- 新世界的猴子进化出独立的红绿色受体,形成了三通道色觉。
- 能够区分红色和绿色,有助于我们在树叶中识别水果。
- 猴子为了采集水果而进化出三色视觉。
这种观点可能并非完全错误,但其逻辑存在缺陷。在采集成熟的水果时,能够区分红色和绿色可能会有帮助,但这是在水果总量丰富、够所有动物吃的情况下。在食物匮乏时,或为了避开有毒浆果以及伪装的捕食者的威胁时,这种对红绿的分辨是否有帮助,还有待考察。虽然这种能力可能在所有这些方面都有所帮助,但我们还没有通过实验来证明这一点。
我的论点虽然有些过分简化,但与猴子视觉的论点不同,其中的重要步骤是可以证明的。其他人已经证明我们在不同的照明条件下能够非常准确地识别颜色。我们可以说,我们拥有这种能力是因为它有用,或者是为了生存而进化的,但这种论点的重要性已不如从前。我们的视觉似乎依赖于“识别出物体,并将其颜色与预期相比较”,而摄影机的白点校正是通过匹配 RGB 三通道的峰值来实现的。但如果两类系统都能把同样的工作做好,那我们就可以把视觉模型建立在我们所理解的更简单的摄影机过程上。人们已经这样做了,并表明我们可能会把连衣裙看成蓝黑色或蓝白+金色,但没有人应该看到其他颜色。他们还展示了哪些照明线索会让我们中的一些人把连衣裙看成蓝白+金色,并通过实验确认了这一点。
这样的假设并不理想。如果能有一个确切的模型来说明我们如何纠正光照的影响,那就更好了。但这很复杂,我不指望我们很快就能有这样的模型。与此同时,我们对颜色恒常性进行建模,就像我们在纠正摄影机图像的不均匀照明一样。这个方法很有效,对目前的讨论而言已经够用了。
透过窗户的所见
当看到模仿真实场景的图像时,我们也会对眼睛和大脑的工作方式有所了解。

在上图中,莫奈画的是在雪地里被夕阳和天空照亮的干草堆。我们知道雪是白色的,然而在这张画里,雪地在阳光下是粉色和橙色的,在阴影中则由于天空反射而呈现蓝色。这张照片的色彩很平衡,给人一种平均白色很合理的感觉。这有时被称为“灰度世界”模型(’grey world’ model),可以用来给摄影机的影像提供一种令人愉悦的色彩平衡。但是,我们该在哪里设定界限?在这幅画作中,干草堆的图像被真正的白色所包围,但雪地的颜色看起来仍然是正确的。我们观看这幅图像,就好像是透过窗户看到的风景一样。
对全局的“灰度世界”模型 [3] 而言,窗户是一个重要例外。想象一下,我们在一个用普通钨丝灯照亮的房间里,从窗户向外观看一个由日光照亮的场景。一个具有单一“灰度世界”白平衡的摄影机,会把房间拍成黄色的,而窗外拍成蓝色的。但我们的视觉会把房间和窗户看做是拥有各自白平衡的独立“世界”。
我们也可以把电脑显示器看做是一个窗口。在 20 世纪 80 年代,印刷色彩管理的早期阶段,人们试图将显示器的白点与环境照明相匹配。虽然这符合灰度世界模型,但看起来很奇怪,显示器看起来是偏橙色(orange)的。如果没有标准的照明设备,那么将办公室照明环境下的印刷样品,与设置为“日光”白平衡的计算机图像进行比较,实际上更加容易也更加“自然”。那时的显示器很少经过校准,但它们有旋钮,可以通过转动来调节至正确的白色。也许莫奈在他的脑海里也是这样做的,所以他的干草堆在房间里的矩形画架上看起来是正确的。对此我并不确定,但在观看窗户、显示器,或其他具有相似边框的形状时,我们对白色的整体感知似乎暂停了。
总结
我们的讨论到这里可以告一段落了。尽管还有许多值得探讨的内容,但等我们了解了关于颜色测量的基础知识后,再阐述这些观点将会更加清晰。现在我来简要总结一下本章的讨论。
- 正常视觉的人眼对光的反应方式大致相似。我们使用标准观察者模型,根据光谱测量预测哪些颜色在与普通观察者的眼中是匹配的,这些模型目前十分有效。
- 我们没有办法测量个人对颜色的内在感受。我们知道,环境会以复杂的方式影响我们感知的颜色:例如,在一个色块中看到什么颜色,取决于该色块是不是香蕉型的,或者在不在阴影里。要做一个标准的观察者模型来模拟这样的效果是很困难的。
- 连衣裙的照片表明,我们可以从相同的刺激中感受到不同的视觉效果。这种戏剧性的分歧虽然罕见,但可以复现,也可以理解。这幅图像之所以产生歧义,是因为我们需要猜测光源的性质,不同的人可能会做出不同的判断。在真实场景中,通常有更多的光线线索,但也可能存在更微妙的变化。
- 我们还没有探讨这个难题:“如果你和我都看着一种红色,我们是否都看到了相同的红色?”虽然很难理解,但你我对红色可能有着非常不同的内在感知。如果我们在观察形似葡萄的色块时想到的是绿色而不是紫色的葡萄,或者是将连衣裙看成白色和金色,那么我们就有了可以衡量的实际差异。如果幸运的话,通过进一步的研究,我们可以找到更多这样的案例并从中学习。但这些都无法告诉我们,红色的 本质 是什么。
- 在制作真实场景的图像时,并不一定要对原始场景的所有颜色和强度进行精确复制。图像可能比原始场景更暗或更亮,色彩可能更少,对比度更低,但仍然能够与原始场景达到良好的匹配。莫奈的干草堆就使用了很少的颜色,却呈现出美妙的效果。我们可以通过简单的视觉模型实现初步的色彩匹配,而熟练的艺术家可以以此为起点,进一步完善这个过程。
- 随着讨论的展开,我们会发现更多的问题。我们可以用标准观察者模型对看到的颜色进行编码。虽然错觉现象表明使颜色外观发生改变的原因有很多,但由于这种外观的偏移难以量化,而且没法知道每个人看到的东西是否一致,因此没有一个“大统一理论(Grand Unified Theory)”来预测所有颜色的外观应该是什么样子。
- 我会尝试描述我们可以测量的东西,比如如何使图像 B 看起来像图像 A,以及类似的话题。我不打算谈论色彩和谐(colour harmony)或构图(composition),但可能会讨论一些特定的图像,因为它们的构图可以说明使它们发挥作用的视觉过程。
- 1.事实上,上面提到的这些错觉,有很多都可以作为反应视网膜侧抑制现象(lateral inhibition)的示例。所谓侧抑制现象,就是指视网膜上相邻感受器之间会存在相互抑制的现象,正是因为这个现象的存在,才导致了同样的一个图案,在不同环境的映衬下会给人不一样的感受。当然,另外一种感性的理论认为,人的视觉系统是非常智能的,对于我们接受到的图案,视觉系统会预先进行视觉补偿处理。比如如果背景太暗,视觉系统会认为既然光线暗了,那么实际看到的物体就会变暗,因此我需要把它的亮度提高,从而得到它真实的亮度。虽然个人觉得这个理论有点牵强附会的意思,不过用这个理论的确可以很自然地解释很多类似的现象。 ↩
- 2.小人谬误(homunculus fallacy,fallacy of the homunculus)是2018年公布的生物物理学名词。一种很容易让人相信的错觉。在一个人意识的中心,存在一个有意识的“微型人”,一直在观察着外部世界,并主导一切行动。 ↩
- 3.灰度世界算法以灰度世界假设为基础,该假设认为:对于一幅有着大量色彩变化的图像,其 RGB 三个色彩分量的平均值趋于同一灰度值 K。 从物理意义上讲,灰色世界法假设自然界景物对于光线的平均反射的均值在总体上是个定值,这个定值近似地为“灰色”。 颜色平衡算法将这一假设强制应用于待处理图像,可以从图像中消除环境光的影响,获得原始场景图像。 ↩
转载请注明来源。欢迎留言评论,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。